
Из каких компонентов состоит банк знаний
Обновлено: 05.05.2024
Банк данных (БнД) – это система специально организованных данных, программных, языковых, организационных и технических средств, предназначенных для централизованного накопления и коллективного многоцелевого использования данных. Под базой данных (БД) обычно понимается именованная совокупность данных, отображающая состояние объектов и их отношений в рассматриваемой предметной области. Характерной чертой баз данных является постоянство: данные постоянно накапливаются и используются; состав и структура данных, необходимых для решения тех или иных прикладных задач, обычно постоянны и стабильны во времени; отдельные или даже все элементы данных могут меняться – но это и есть проявление постоянства – постоянная актуальность.
Услугами БнД пользуется обычно большое число пользователей. Поэтому в БнД предусматривается специальное средство приведения всех запросов к единой терминологии — словарь данных. Кроме того, используются специальные методы эквивалентных грамматических преобразований запросов для построения оптимальных процедур их обработки, специальные методы доступа к одним и тем же данным различных пользователей при совпадении во времени поступивших запросов — механизм транзакций.
Состав и структура банка данных. Назначение основных компонентов банка данных.
Обычно со стороны внешних пользователей к БнД формулируются следующие требования. БнД должен:
• Удовлетворять актуальным информационным потребностям внешних пользователей, обеспечивать возможность хранения и модификации больших объемов многоаспектной информации.
• Обеспечивать заданный уровень достоверности хранимой информации.
• Обеспечивать доступ к данным только пользователям с соответствующими полномочиями.
• Обеспечивать возможность поиска информации по произвольной группе признаков.
• Удовлетворять заданным требованиям по производительности при обработке запросов.
• Иметь возможность реорганизации и расширения при изменении границ ПО.
• Обеспечивать выдачу информации пользователю в различной форме.
• Обеспечивать простоту и удобство обращения внешних пользователей за информацией.
• Обеспечивать возможность одновременного обслуживания большого числа внешних пользователей.
Преимущества централизации управления данными:
• Сокращение избыточности хранимых данных (минимально необходимых — дублирование данных).
• Устранение противоречивости хранимых данных (хранимых в различных файлах).
• Многоаспектное использование данных (принцип однократного ввода данных для разных пользователей и приложений).
• Комплексная оптимизация. (Например, выбор структуры хранения данных, которая обеспечивает наилучшее обслуживание в целом). В максимальной степени удовлетворяются противоречивые требования.
• Обеспечение возможности стандартизации (упрощение обмена данных, контроля и восстановления данных).
• Обеспечение возможности санкционированного доступа к данным. Интеграция данных приводит к тому, что данные, используемые различными пользователями, могут пересекаться различным образом. Следовательно, важно наличие в этих условиях механизма защиты данных от несанкционированного доступа к ним.
БнД через СУБД обеспечивает независимость прикладных программ от данных, чтобы не выполнять трудоемких ручных операций по внесению соответствующих изменений в прикладные программы.
Рассматривая данные как один из ресурсов АС (автоматизированных систем), можно сказать, что БнД централизованно управляет этим ресурсом в интересах всей системы. Наличие централизованного управления данными — главная отличительная черта БнД.
БнД — информационная система, реализующая централизованное управление данных в интересах всех пользователей АС. (Средство интеграции данных).
БнД — может рассматриваться в узком и широком смысле этого понятия. В узком БнД=БД + СУБД. В широком БнД =АС (автоматизированная система).
БнД в узком смысле включает в состав две основные компоненты:
• БД;
• СУБД — для реализации централизованного управления данными, хранимыми в базе, доступа к ним, поддержание их в состоянии, соответствующем состоянию ПО.
В широком смысле БнД — это АС.
1.4 Изучение таблицы в режиме конструктора
Открытие таблицы в режиме конструктора позволяет увидеть подробную структуру таблицы. Например, можно найти настройку типа данных для каждого поля, любые маски ввода или узнать, используются ли в таблице какие-либо поля подстановки — поля, которые используют запросы для извлечения данных из других таблиц. Эти сведения полезны, поскольку типы данных и маски ввода могут повлиять на возможность поиска данных и запуска запросов на обновление. Например, нужно использовать запрос на обновление для обновления определенных полей в одной таблице посредством копирования данных в сходные поля из другой таблицы. Запрос не будет выполняться, если типы данных для каждого поля в исходной и конечной таблицах не совпадают.
1.Откройте базу данных, которую нужно проанализировать.
2.В области переходов щелкните правой кнопкой мыши таблицу, которую хотите изучить, и затем в контекстном меню выберите Конструктор.
3.Просмотрите название каждого поля таблицы и тип данных, назначенный каждому полю.
Тип данных, назначенный полю, может ограничивать размер и тип данных, вводимых пользователями в это поле. Например, количество знаков, вводимых пользователями в текстовое поле, может быть ограничено 20 знаками или нельзя вводить текстовые данные в поле, настроенное с типом данных «Числовой».
4.Чтобы определить, является ли поле полем подстановки, щелкните вкладку Подстановка в нижнем разделе таблицы, озаглавленномСвойства поля.
Поле подстановки отображает одно множество значений (одно или несколько полей, таких как имя и фамилия), но обычно в нем хранится другое множество значений (одно поле, такое как числовой ИД). Например, поле подстановки может хранить номер ИД клиента (хранимое значение), но отображать имя клиента (отображаемое значение). Когда поле подстановки используется в выражениях или операциях поиска и замещения, используется хранимое значение, а не отображаемое значение. Изучение хранимых и отображаемых значений поля подстановки поможет вам добиться того, чтобы выражения или операции поиска и замещения, использующие поля подстановки, работали должным образом.
На следующей иллюстрации показано типичное поле подстановки. Помните, что настройки, отображаемые в свойстве Источник строк этого поля, будут изменяться.
Показанное на рисунке поле подстановки использует запрос для извлечения данных из другой таблицы. Можно также увидеть другой тип поля подстановки, которое называется списком значений и использует жестко закодированный список вариантов. На рисунке показан типичный список значений.
По умолчанию списки значений используют тип данных «Текстовый».
Лучший способ найти списки значений и подстановки — перейти на вкладку Подстановка и затем щелкнуть записи в столбце Тип данных для каждого поля в таблице.
Статьи к прочтению:
Банк данных исполнительных производств
Похожие статьи:
РАБОТА С БАЗАМИ ДАННЫХ Содержание лекции- 1.Основные понятия баз данных. Базы данных и системы управления базами данных. 2.Структура простейшей базы…
Лабораторная работа №16 Реализация механизма создания коллекции и применение коллекций в программах Цель работы: Научиться разрабатывать программы,…
Банк данныхявляется разновидностью ИС, в которой реализованы функции централизованного хранения и накопления обрабатываемой информации, организованной в одну или несколько баз данных.
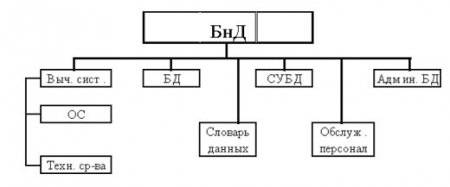
Банк данных (БнД) в общем случае состоит из следующих компонентов: базы (нескольких баз) данных, системы управления базами данных, словаря данных, администратора, вычислительной системы и обслуживающего персонала. Вкратце рассмотрим названные компоненты и некоторые связанные с ними важные понятия.
База данных(БД) представляет собой совокупность специальным образом организованных данных, хранимых в памяти вычислительной системы и отображающих состояние объектов и их взаимосвязей в рассматриваемой предметной области.
Логическую структуру хранимых в базе данных называют моделью представления данных. К основным моделям представления данных (моделям данных) относятся следующие: иерархическая, сетевая, реляционная, постреляционная, многомерная и объектно-ориентированная.
По способу организации доступа к данным базы данных подразделяют на централизованные и распределенные.
Централизованные БД хранятся в памяти одной машины, но возможен распределенный доступ к ней с различных рабочих станций сети.
Распределенная БД состоит из нескольких частей, хранимых на разных ЭВМ вычислительной сети.
Система управления базами данных(СУБД) — это комплекс языковых и программных средств, предназначенный для создания, ведения и совместного использования БД многими пользователями. Обычно СУБД различают по используемой модели данных. Так, СУБД, основанные на использовании реляционной модели данных, называют реляционными СУБД.
Словарь данных(СД) представляет собой подсистему БнД, предназначенную для централизованного хранения информации о структурах данных, взаимосвязях файлов БД друг с другом, типах данных и форматах их представления и т.п.
Администратор базы данных(АБД) есть лицо или группа лиц, отвечающих за выработку требований к БД, ее проектирование, создание, эффективное использование и сопровождение. В процессе эксплуатации АБД обычно следит за функционированием информационной системы, обеспечивает защиту от несанкционированного доступа, контролирует избыточность, непротиворечивость, сохранность и достоверность хранимой в БД информации.
Вычислительная система(ВС) представляет собой совокупность взаимосвязанных и согласованно действующих ЭВМ или процессоров и других устройств, обеспечивающих автоматизацию процессов приема, обработки и выдачи информации потребителям.
Обслуживающий персоналвыполняет функции поддержания технических и программных средств в работоспособном состоянии. Он проводит профилактические, регламентные, восстановительные и другие работы по планам, а также по мере необходимости.
Классификация СУБД.В общем случае под СУБД можно понимать любой программный продукт, поддерживающий процессы создания, ведения и использования БД.
Рассмотрим, какие из имеющихся на рынке программ имеют отношение к БД и в какой мере они связаны с базами данных.
К СУБД относятся следующие основные виды программ:
•средства разработки программ работы с БД.
По характеру использования СУБД делят на персональные и многопользовательские.
Персональные СУБДобычно обеспечивают возможность создания персональных БД и недорогих приложений, работающих с ними. Персональные СУБД или разработанные с их помощью приложения зачастую могут выступать в роли клиентской части многопользовательской СУБД. К персональным СУБД, например, относятся VisualFoxPro, Paradox, Clipper, dBase, Access и др.
Многопользовательские СУБДвключают в себя сервер БД и клиентскую часть и, как правило, могут работать в неоднородной вычислительной среде (с разными типами ЭВМ и операционными системами). К многопользовательским СУБД относятся, например, СУБД Oracle и Informix.
По используемой модели данных СУБД (как и БД), разделяют на иерархические, сетевые, реляционные, объектно-ориентированные и другие типы. Некоторые СУБД могут одновременно поддерживать несколько моделей данных.

С точки зрения пользователя, СУБД реализует функции хранения, изменения (пополнения, редактирования и удаления) и обработки информации, а также разработки и получения различных выходных документов.
Для работы с хранящейся в базе данных информацией СУБД предоставляет программам и пользователям следующие два типа языков:
- язык описания данных — высокоуровневый непроцедурный язык декларативного типа, предназначенный для описания логической структуры данных;
- язык манипулирования данными — совокупность конструкций, обеспечивающих выполнение основных операций по работе с данными: ввод, модификацию и выборку данных по запросам.
Перечисленные выше функции СУБД, в свою очередь, используют следующие основные функции более низкого уровня, которые назовем низкоуровневыми:
• управление данными во внешней памяти;
•управление буферами оперативной памяти;
• управление транзакциями;
• ведение журнала изменений в БД;
• обеспечение целостности и безопасности БД.
Дадим краткую характеристику необходимости и особенностям реализации перечисленных функций в современных СУБД.
Реализация функции управления данными во внешней памятив разных системах может различаться и на уровне управления ресурсами. В основном методы и алгоритмы управления данными являются «внутренним делом» СУБД и прямого отношения к пользователю не имеют.
Необходимость буферизации данных и как следствие реализации функции управления буферамиоперативной памяти обусловлено тем, что объем оперативной памяти меньше объема внешней памяти.
Буферы представляют собой области оперативной памяти, предназначенные для ускорения обмена между внешней и оперативной памятью. В буферах временно хранятся фрагменты БД, данные из которых предполагается использовать при обращении к СУБД или планируется записать в базу после обработки.
Механизм транзакций используется в СУБД для поддержания целостности данных в базе. Транзакцией называется некоторая неделимая последовательность операций над данными БД, которая отслеживается СУБД от начала и до завершения. Если по каким-либо причинам (сбои и отказы оборудования, ошибки в программном обеспечении, включая приложение) транзакция остается незавершенной, то она отменяется.
Транзакции присущи три основных свойства:
• атомарность (выполняются все входящие в транзакцию операции или ни одна);
• сериализуемость (отсутствует взаимное влияние выполняемых в одно и то же время транзакций);
• долговечность (даже крах системы не приводит к утрате результатов зафиксированной транзакции).
Примером транзакции является операция перевода денег с одного счета на другой в банковской системе. Здесь необходим, по крайней мере, двухшаговый процесс. Сначала снимают деньги с одного счета, затем добавляют их к другому счету. Если хотя бы одно из действий не выполнится успешно, результат операции окажется неверным и будет нарушен баланс между счетами.
Контроль транзакций важен в однопользовательских и в многопользовательских СУБД, где транзакции могут быть запущены параллельно.
Ведение журнала измененийв БД (журнализация изменений) выполняется СУБД для обеспечения надежности хранения данных в базе при наличии аппаратных сбоев и отказов, а также ошибок в программном обеспечении.
Журнал СУБД — это особая БД или часть основной БД, непосредственно недоступная пользователю и используемая для записи информации обо всех изменениях базы данных. В различных СУБД в журнал могут заноситься записи, соответствующие изменениям в СУБД на разных уровнях: от минимальной внутренней операции модификации страницы внешней памяти до логической операции модификации БД (например, вставки записи, удаления столбца, изменения значения в поле) и даже транзакции.
Для эффективной реализации функции ведения журнала изменений в БД необходимо обеспечить повышенную надежность хранения и поддержания в рабочем состоянии самого журнала. Иногда для этого в системе хранят несколько копий журнала.
Обеспечение целостности БД составляет необходимое условие успешного функционирования БД, особенно для случая использования БД в сетях.
ЦелостностьБД есть свойство базы данных, означающее, что в ней содержится полная, непротиворечивая и адекватно отражающая предметную область информация. Поддержание целостности БД включает проверку целостности и ее восстановление в случае обнаружения противоречий в базе данных. Целостное состояние БД описывается с помощью ограничений целостности в виде условий, которым должны удовлетворять хранимые в базе данные. Примером таких условий может служить ограничение диапазонов возможных значений атрибутов объектов, сведения о которых хранятся в БД, или отсутствие повторяющихся записей в таблицах реляционных БД.
Обеспечение безопасностидостигается в СУБД шифрованием прикладных программ, данных, защиты паролем, поддержкой уровней доступа к базе/данных и к отдельным ее элементам (таблицам, формам, отчетам и т. д).
Архитектура СУБД.
В современных системах БД выделяют 3 уровня представления данных: внешний, концептуальный и внутренний (рис. 1.3). Внешний уровень отражает представление пользователей на БД. Внутренний уровень отражает представление, на котором СУБД и ОС воспринимают данные. Концептуальный (логический) уровень – связан с обобщенным представлением всех пользователей БД ( это взгляд администратора БД).
Внешний уровень – это пользовательский уровень. Пользователем может быть программист, конечный пользователь или администратор БД. Представление с точки зрения пользователя называется внешним представлением. Оно отражает представление пользователя о данных в БД в удобной для него форме (например, для бухгалтерии - это данные о студентах, которым начисляется стипендия, при этом не важно, какие у них оценки. Для деканата данные о тех же студентах будут содержать сведения об их оценках в сессию и т.п.) . Эти частичные представления пользователей о БД называют подсхемой БД. При этом каждый пользователь может использовать свои языковые и программные средства для работы с БД.
Концептуальный уровень является промежуточным уровнем и обеспечивает представление всей БД в абстрактной форме. Описание БД на этом уровне называют концептуальной схемой , которая является результатом концептуального проектирования. Концептуальная схема отражает интересы всех пользователей и представляет собой единое логическое описание всех элементов данных и отношений между ними, образуя логическую структуру всей БД.
Концептуальная схема должна содержать:
· объекты и атрибуты предметной области;
· связи между объектами;
· ограничения, накладываемые на данные;
· семантическую информацию о данных;
· обеспечение безопасности данных;
· поддержку целостности данных.
Концептуальный уровень поддерживает каждое внешнее представление, в том смысле, что любые доступные пользователю данные должны содержаться (или могут быть вычислены) на этом уровне. Однако на этом уровне не содержаться сведения о методах хранения данных.
Внутренний уровень характеризует внутреннее представление. Оно не связано с физическим уровнем, т.к. физический уровень хранения информации обладает существенной индивидуальностью для каждой системы. На внутреннем уровне все эти особенности не учитываются, а вся область хранения представляется как бесконечное линейное адресное пространство. На нижнем уровне находится внутренняя схема, которая является полным описанием внутренней модели данных. Для каждой БД она только одна. Внутренняя схема описывает физическую реализацию и предназначена для достижения оптимальной производительности и обеспечения экономного использования дискового пространства. На внутреннем уровне хранится следующая информация:
· распределение дискового пространства для хранения данных и индексов;
· описание подробностей сохранения записей (типы, размеры элементов данных и др.);
· сведение о размещении записей;
· сведения о сжатии записей и выбранных методах шифрования.
СУБД отвечает за установление соответствия между всеми тремя уровнями и поддержку их непротиворечивости.
В структуре программного комплекса СУБД можно выделить:
Процессор запросов – преобразует запросы в последовательность низкоуровневых инструкций для контроллера БД.
Транслятор с ЯОД – преобразует его команды в набор таблиц, содержащих метаданные. Эта информация хранится в системном каталоге, а управляющая информация – в заголовке файлов.
Транслятор с ЯМД – преобразует внедренные в прикладные программы операторы в вызовы стандартных функций базового языка. Взаимодействует с процессором запросов.
Банк данных - это система специальным образом организованных данных (баз данных), программных, технических, языковых, организационно-методических средств, предназначенных для обеспечения централизованного накопления и коллективного многоцелевого использования данных.
Компоненты банка данных: информационная компонента, программные средства, языковые средства, технические средства, организационно- методические средства, СУБД, администратор БнД. Основные компоненты БД и СУБД.
Классификация банков данных. Центральной компонентой банка данных является БД, И большинство классификационных признаков относятся именно к ней.
1. По форме представляемой информации различают видео- и аудиосистемы а также системы мультимедиа. Эта классификация в основном показывает, в каком виде информация из баз данных выдается пользователям в виде изображения, звука или дается возможность использования разных форм отображения информации.
Наибольшее практическое использование находят базы данных, содержащие обычные символьные данные. Эти базы данных, в свою очередь, могут быть разделены на неструктурированные(базы, организованные в виде семантических сетей) , частично структурированные ( базы данных в виде обычного текста или гипертекстовые системы.) и структурированные.
2 Структурированные БД, в свою очередь, по типу используемой модели делятся на иерархические, сетевые, реляционные, смешанные и мультимодельные. Наибольшее использование имеют реляционные системы. Классификация по типу модели распространяется не только на базы данных, но и на СУБД и даже на банк данных в целом.
3По типу хранимой информации БД делятся на документальные, фактографические и лексикографические. Среди документальных баз различают библиографические, реферативные и полнотекстовые. К лексикографическим базам данных относятся различные словари (классификаторы, многоязычные словари, словари основ слов и т. п.).
4 По характеру организации хранения данных и обращения к ним различаютлокальные (персональные),общие (интегрированные) ираспределенные базы данных .
Базы данных могут классифицироваться по охвату предметной области .
Требования к банкам данных
Особенности «банковской» организации данных позволяют формулировать основные требования, предъявляемые к БнД:
1) адекватность отображения предметной области (полнота, целостность и непротиворечивость данных, актуальность информации, т. е. ее соответствие состоянию объекта на данный момент времени);
2) возможность взаимодействия пользователей разных категорий и в разных режимах, обеспечение высокой эффективности доступа для разных приложений;
3) дружелюбность интерфейсов и малое время на освоение системы, особенно для конечных пользователей
4) обеспечение секретности и конфиденциальности для некоторой части данных; определение групп пользователей и их полномочий;
5) обеспечение взаимной независимости программ и данных;
6) обеспечение надежности функционирования БнД; защита данных от случайного и преднамеренного разрушения; возможность быстрого и полного восстановления данных в случае их разрушения; технологичность обработки данных, приемлемые характеристики функционирования БнД (стоимость обработки, время реакции системы на запросы, требуемые машинные ресурсы и др.).
Банк данных является разновидностью ИС, в которой реализованы функции централизованного хранения и накопления обрабатываемой информации организованной в одну или несколько баз данных.
Банк данных в общем случае состоит из следующих компонентов:
1. БД - представляет собой совокупность специальным образом организованных данных хранимых в памяти ВС и отображающих состояние объектов и их взаимосвязи в рассматриваемой предметной области.
Логическую структуру хранимых в БД данных называют моделью представления данных. К основных моделям представления данных относятся: иерархическая, сетевая, реляционная, постреляционная, многомерная и объектно-ориентированная.
2. СУБД – это комплекс языковых и программных средств, предназначенных для создания, ведения и совместного использования базы данных многими пользователями.
Обычно СУБД различают по используемой модели данных.
3. Приложения – представляют собой программу или комплекс программ, обеспечивающий автоматизацию обработки информации для прикладной задачи. Их разрабатывают в случаях, когда требуется обеспечить удобство работы с БД неквалифицированным пользователям или интерфейс СУБД не устраивает пользователя.
4. Словарь данных – представляет собой подсистему банка данных, предназначенную для централизованного хранения информации о структурах данных, взаимосвязях файлов друг с другом, типах данных, форматах их представления, принадлежности данных пользователям, кодах защиты и разграничении доступа.
5. Администратор БД – есть лицо или группа лиц, отвечающее за выбор требований к БД, ее проектирование, создание, эффективное использование и сопровождение.
В процессе использования администратор следит за функционированием информационной системы, обеспечивает защиту, контролирует избыточность, непротиворечивость, сохранность и достоверность хранимой в БД информации.
6. ВС– представляет собой совокупность взаимосвязанных и согласованно действующих компьютеров и других устройств, обеспечивающих автоматизацию процессов приема, обработки и выдачи информации потребителю.
7. Обслуживающих персонал – выполняет функции поддержания работы технических и программных средств, работоспособность их состояния
Иерархическая модель данных
Иерархическая модель данных – это логическая модель данных в виде древовидной структуры. Иерархическая древовидная структура строится из узлов и ветвей.
Узелпредставляет собой совокупность атрибутов данных описывающих некоторый объект.
Корень - наивысший узел в древовидной структуре.
Зависимые узлы располагаются на более на более низких уровнях дерева. Уровень, на котором находиться данный узел определяется расстоянием от корневого узла.
Каждый экземпляр корневого узла образует начало записи логической БД. В иерархической модели данных узлы, находящиеся на уровне 2, называются порожденными узла на уровне1, узел на уровне1 называется исходнымдля узлов на уровне 2.
Достоинства:
· Наличие хорошо зарекомендовавших себя СУБД основанных на её применении.
· Простота понимания и использования.
· Обеспечение определенного уровня независимости данных.
· Простота оценки операционных характеристик благодаря заранее заданным взаимосвязям.
Недостатки:
· Удаление исходных объектов влечет удаление поражденных.
· Особенности иерархических структур обуславливают процедурность операций манипулирования данными.
· Сложность доступа к узлам.
Сетевая модель данных
Сетевая модель состоит из множества записей, которые могут быть владельцами или членами групповых соотношений. Связь между записью владельцем и записью объектом имеет вид 1:N/
Сетевая модель –структура,у которой любой элемент может быть связан с любым другим элементом.
Атрибут -логическая единица структуры данных. Обычно каждому элементу при описании БД присваивается уникальное имя. По имени к нему обращаются при обработке.
Элемент данных так же часто называют полем.
Запись– именованная совокупность атрибутов. Использование записей позволяет за одно обращение к базе получить некоторую логически связанную совокупность данных. Именно записи изменяются, добавляются и удаляются. Тип записи определяется составом ее атрибутов.
Экземпляр записи – это конкретная запись с конкретным значением элементов. Примеры сетевых СУБД: CODASYL, DBMS, IDMS, TOTAL, VISTA, СЕТЬ, СЕТОР, КОМПАС.
Достоинство сетевой модели – высокая эффективность затрат памяти и оперативность.
Недостатки:
1. Сложность и жесткость схема базы данных, а так же сложность понимания.
2. Ослабленный контроль целостности ( допускается устанавливать произвольные связи между записями ).
3. Сложность механизма доступа к данным.
4. Необходимость на физическом уровне четко определять связи данных.
5. Требуются значительные ресурсы памяти ЭВМ.
6. Сложность реализации СУБД.
Реляционная модель
Реляционная модель была предложена в 1970 году Эдгаром Кодом и основывалась на понятиях «отношений». Отношения представляют собой множество элементов называемых кортежами. Наглядной формой представления отношений является двумерная таблица. Таблица имеет строки называемые записями и столбцы – колонки. Каждая строка таблицы имеет одинаковую структуру и состоит из полей. Строкам таблицы соответствуют кортежи, а столбцам – атрибуты отношений. С помощью одной таблицы удобно описать простейший вид связей между данными, информация о которых хранится в таблице. Так как в рамках одной таблицы не удается описать более сложной логической структуры данных из предметной области применяют связывание таблицы.
Достоинства реляционной модели:
1. Простота, удобство физической реализации, понятность.
2. Легко дополнять простыми отношениями.
Недостатки:
1. Отсутствие стандартных средств, идентификация отдельных записей.
2. Сложность описания, иерархической и сетевой связи.
Классификация программ СУБД
В общем случае под СУБД можно понимать любой программный продукт, поддерживающий процесс создания, ведения и использования БД.
В общем случае СУБД делятся на следующие основные виды программ:
1. Полнофункциональные (ПФ) – представляют собой традиционные СУБД. Из числа всех современных СУБД ПФ являются наиболее многочисленными и мощными по своим возможностям. К ПФ относятся Data Flex, dBase, Access, FoxPro, Paradox. Обычно ПФ СУБД имеет развитый интерфейс, позволяющий с помощью команд меню выполнять основные действия с СУБД:
1) Создание, модификация структур и таблиц.
3) Формирование запросов.
4) Разработка отчетов и их печать.
Многие ПФ СУБД включают в себя средства программирования для профессиональных разработчиков.
2. Серверы БД предназначены для организации центров обработки данных в сетях ЭВМ. Серверы БД реализуют функцию управления БД запрашиваемые другими пользователями обычно с помощью SQL запросов ( операторов ). К серверам баз данных относятся SQL-server и InterBase.
3. Клиенты БД.В роли клиентских программ для сервера БД могут использоваться различные программы: ПФ СУБД и электронные таблицы.
4. Средства разработки программ работы с БД – могут использоваться для создания разновидностей следующих программ: клиентских программ, серверов БД и их отдельных компонентов, пользовательских приложений. К средствам разработки пользовательских приложений относятся: системы программирования, разнообразные библиотеки программ для различных языков программирования, а так же пакеты автоматизации разработок ( в том числе системах типа «клиент-сервер» (Delphi, Builder, Visual Basic ).
По характеру использования СУБД делятся на:
1. Персональные СУБД – обеспечивают возможность создания персональных баз данных и недорогих приложений работающих с ними. Они выступают в роли клиентской части многопользовательских СУБД ( FoxPro, Acces и dBase).
2. Многопользовательские СУБД – включают в себя сервер БД и клиентскую часть. Как правило они могут работать в неоднородной вычислительной среде ( с разными типами ЭВМ и ОС): Oracle.
Создавая базу знаний, каждый преследует свои цели и решает свои проектные задачи, использует свои инструменты и программные средства. Однако для чего бы и с помощью чего бы не создавалась база знаний, она обязательно должна приносить компании максимальную пользу. Как этого добиться?
В сентябре 2020 года я выступила спикером IV-й конференции «Управление корпоративными знаниями», проходившей в рамках недели корпоративного обучения. Мой мастер-класс «Как создать корпоративную базу знаний, чтобы она стала «интеллектуальным активом» компании» заинтересовал собравшихся, и я решила сделать из материалов выступления статью. Буду рада если текст поможет вам в работе. Буду рада, если кто-то из вас захочет в комментариях обсудить этот пост.

Источник
Универсального сценария «Как создать базу знаний», который бы подходил всем и всегда, нет и быть не может. Обусловлено это как разными подходами к организации баз, так и разными IT-инструментами. А вот общие требования, своеобразный cookbook, – как раз предмет моей статьи.
Опыт большого многоуровневого проекта поддержки информационной системы позволяет выделить три основных принципа, лежащих в основе любой успешной базы знаний. Она должна быть:
Написать понятно для всех

Текст статьи из базы знаний должен быть понятен всем, кто будет её читать. Притом понятен с первого прочтения, ибо скорее всего второй раз её читать просто не будут. Статья не должна быть слишком длинной или чрезмерно короткой. Материал должен быть изложен так, чтобы трактовки его содержания были однозначными, и не нужно было переводить с «бухгалтерского» или «IT-шного» на «человеческий».
Например, статья, описывающая решение типовой проблемы, написанная в стиле «… перед входом в личный кабинет очистите кэш», скорее всего вызовет вопросы, а вот если дополнить его алгоритмом очистки кэша, написанным «для вашей бабушки», то ответ будет понятен всем.
Ситуация становится острее, когда база знаний используется как FAQ для внешних пользователей, уровень подготовки которых разнится от бабушек и дедушек, которые не смогли освоить смартфон, до суперпрофессионалов этой области.
На первый взгляд, кажется, что достичь этого невозможно: если статья написана для «чайника», то погруженному в тему она будет избыточной, а если ориентироваться на профи, то «чайнику» потребуется «перевод». Как быть?
Есть много инструментов, помогающих решить проблемы. В Департаменте корпоративных систем ЛАНИТ мы используем три подхода.
1. Ревью от ведущего эксперта предметной области. Процесс направлен на повышение качества материалов базы знаний (далее БЗ). Суть в том, что эксперт проверяет корректность изложения материала, в том числе логичность и последовательность изложения.

3. Структурирование. Этот инструмент условно можно разделить на два типа воздействий:
- административное воздействие – регламентированный порядок изложения в едином стиле, порядок фиксации изменений, дополнений и т. п.;
- технические решения – использование макросов и надстроек, позволяющих раскрывать подробности и расшифровки только в случае, если в них есть необходимость. Это решает вопрос разного уровня подготовки читателей: для специалиста статья будет максимально коротко изложенной на языке профессиональных требований, а для новичка будет содержать расшифровки терминов и ссылки на статьи по смежным вопросам.

Всегда актуально
Однажды разместив информацию в базе знаний, нужно всегда поддерживать её в актуальном состоянии. У всех пользователей базы знаний всегда должно быть доверие к материалам, размещенным в ней.

По сути, knowledge manager должен иметь свою систему мониторинга, в которой будут свои триггеры и четко описанные алгоритмы реагирования.
Например, для базы знаний службы поддержки информационной системы триггером будет служить выход новой версии, изменение законодательства и т. п. Разработка набора триггеров и действий при их наступлении, а также определение ответственных за их выполнение – задача, решение которой обеспечивает значительную долю успеха базы знаний.
Сработавший триггер означает, что нужно оперативно скорректировать материалы. Для того, чтобы обновление не стало кошмаром, на этапе размещения материалов необходимо продумать, как оптимизировать количество статей и при необходимости автоматически отбирать нужные по заданным параметрам.
В качестве инструмента, позволяющего осуществить автоматический отбор статей, мы используем классификаторы и статусы (статусная модель с определенным алгоритмом переходов). При этом сложная задача – создание классификаторов так, чтобы их состав был достаточным, но не избыточным.
Пример статусной модели:

Как не создать информационную «мусорку» вместо базы знаний
Статьи, отвечающие на неактуальные вопросы или имеющие узко сформулированные заголовки, – путь к созданию информационной «мусорки» вместо базы знаний. Заголовок, сформулированный недостаточно широко, означает, что в нужный момент найти такую статью смогут только те, кто знает, что она есть в базе знаний. Остальные начнут решать задачу с нуля и создадут на основании этого решения статью-дубль.
Например, заголовок «Шаблоны заявлений» вполне корректен, но сформулирован узко. Искать будет легче, если добавить в него ключевые слова и написать так: «Шаблоны заявлений: отпуск, отгул, удаленная работа, увольнение, перевод».
Статьи, собранные по принципу Lego из констант и переменных, снижают затраты на базу знаний
Есть правило, к которому мы пришли не сразу, но которое значительно экономит время на поддержание актуальности базы знаний. Это правило – никакого дублирования! Информация фиксируется один раз, далее используются ссылки на нее. Технически есть масса возможностей «вживлять» константы в нужные места по тексту статьи так, чтобы читатель даже не знал о том, что статья как конструктор состоит из частей.

Почему «не летит»
Даже самая актуальная база знаний, содержащая ответы на все востребованные вопросы, может «не взлететь», если найти нужную информацию сложно.
Решить проблему поиска можно структурированием и многоуровневой классификацией. Причём классификация должна быть не только на уровне разделов каталога БЗ, но и с метками по разным тематикам (например, если у нас база знаний службы поддержки пользователей, то по темам, личным кабинетам и т.д.). Каждый пользователь может отобрать перечень статей по заданным критериям, используя форму расширенного поиска.
Для того, чтобы поиск был максимально качественным для конкретного пользователя в базе знаний реализована ролевая модель доступа. Это, во-первых, решает вопрос потенциальной утечки информации: пользователю доступны только те материалы, которые подходят ему по роли в проекте или в организации в целом, а, во-вторых, сужают перечень материалов, среди которых производится поиск, повышая качество результатов.
Мобильность — наше всё
Для мобильности и в силу популярности Telegram дополнительно развиваем чат-бота.

Бот реализован в Telegram и доступен с любого устройства пользователя. Уровень доступа к информации через бот соответствует уровню доступа к сервисам компании. По запросу ответ можно получить в том числе из wiki.
Каждый ответ можно оценить. Система оценок позволяет своевременно корректировать как ответы, так и классификаторы. Вопросы, ответы на которые найдены не были, собираются отдельно и выступают идеями для развития базы знаний.
Рассмотренные принципы – не исчерпывающий список требований к базе знаний, сформулированный за четыре года активной работы над несколькими проектами, в том числе над базой знаний службы поддержки большой государственной информационной системы. Кроме того, следует отметить, что все принципы и правила работают тогда, когда в базе знаний заинтересованы все её пользователи и авторы. Главные метрики для оценки заинтересованности — количество использованных в работе материалов и количество правок от каждого автора. Мой личный список требований постоянно расширяется и в последний год появляется всё больше нюансов к требованию структурирования статей. Охотно поделюсь им в следующей статье.
Автор статьи

Читайте также: